数据库系统
模块一:数据库基本概念
四个基本概念
- data / 数据:基本对象,描述事物的符号记录
- database / 数据库:collection of interrelated data items / 长期储存在计算机内,有组织的、可共享的大量数据集合
- database management system / 数据库管理系统:DBMS,位于用户与操作系统之间的数据管理软件。
- database system / 数据库系统: 包括database、dbms、hardware 及 operators
View of data / 数据视图
- View Level:视图层,隐藏细节与隐私
- Logical Level: 逻辑层,描述数据及关系
- Physical Level:物理层,描述怎么存储
Instance & Schemas
- Instance:actual content
- Schemas:Logical Structure of Database
Data Models / 数据模型
- 用于描述:Data、Data relationships、Data semantics、Data constraints
- ER模型:Relational Model 关系模型、面向对象的数据模型、XML
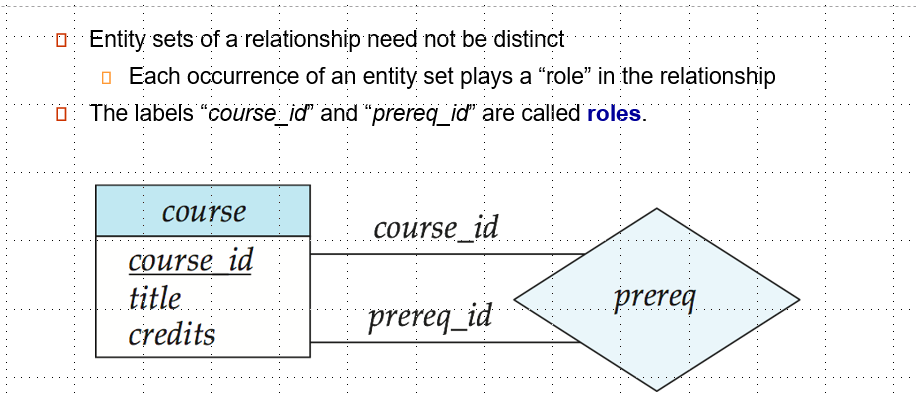
ER模型描述了Entity / 实体 之间的Relationship / 关系。
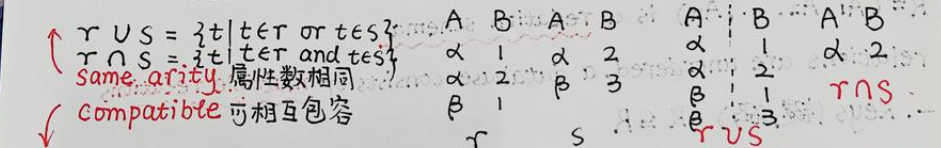
Languages / 语言
- DDL:Data Definition Language 数据定义语言
- DML:Data Manipulation Language 数据操作语言
- SQL:Structured Query Language 结构化查询语言
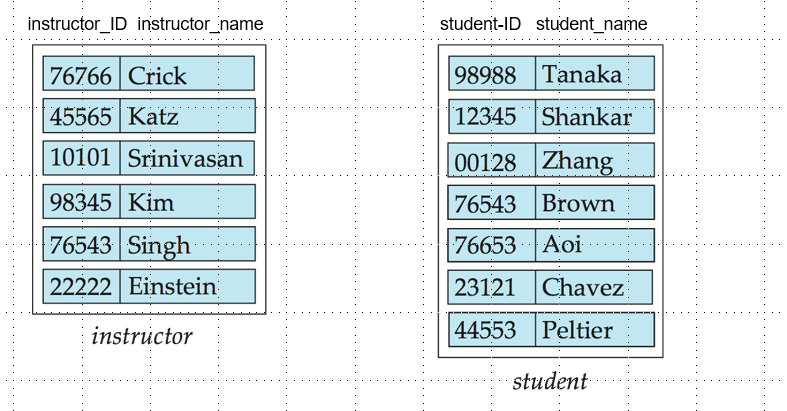
Relational Model / 关系模型

第一行是关系模型的属性 / Attribution 的集合;
第二行是关系模型的元组 / Tuple 的集合;
domain: Set of allowed values for each attribute / 每个属性的允许值的集合,也就是某一列的值的集合。
null member of all domains
Relation Schema: R(A1, A2, …, An) / 关系模式
keys / 键(码)
- Superkey:A set of attributes that uniquely identifies a tuple in a relation / 一个属性集合,可以唯一标识一个元组
- Candidate Key:A minimal superkey / 最小的超键
- Primary Key:A candidate key chosen by the database designer to uniquely identify tuples / 数据库设计者选择的候选键,用于唯一标识元组
- Foreign Key:An attribute in a relation that is a primary key in another relation / 另一个关系中的主键。外码是一个属性,和另外一个表中的主键值相同。
模块二:关系代数
1. select 选择
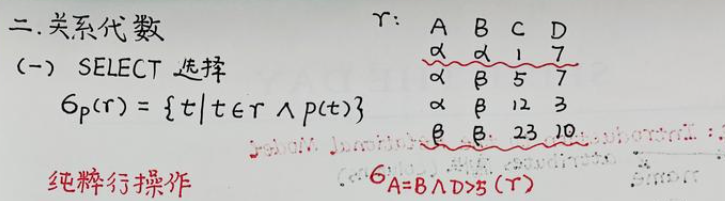
2. project 投影
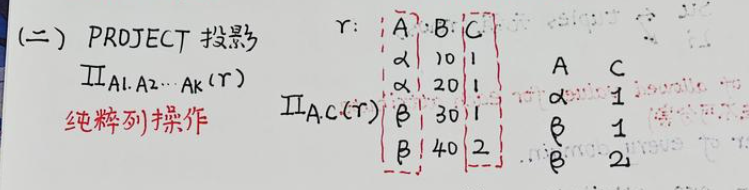
3. unio 联合,intersection 交集,difference 差集
4. rename 重命名

5. cartesian product 笛卡尔积
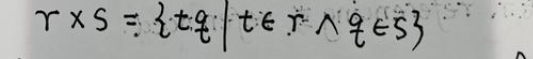

6. natural join 自然连接
对于每一行去找到另一个表中的匹配行,然后将两行合并成一行。

模块三:Sql语言
1. create table construct
1
2
3
4
5
create table schema_of_relation_r
(
attribute_name data_type,
...
);
Domain Types:
- char(n): 定长字符串,长度为n;
- varchar(n): 变长字符串,最大长度为n;
- int: 整数;
- smallint: 小整数;
- numeric(p,d):定点数;p表示总的位数,d表示小数点后的位数;
- real, double precision: 浮点数和双精度浮点数;
- float(n): 浮点数,n表示有效位数;
类型定义:
- not null: 属性值不能为空;
- primary key(A_1, A_2, …): 主键;
- foreign key(A_1, A_2, …): 外键;
1
2
3
4
5
6
create table takes (
ID varchar(5),
course_id varchar(8),
sec_id varchar(8),
semester varchar(6),
year numeric(4,0),
grade varchar(2),
primary key (ID, course_id, sec_id, semester, year),
foreign key (ID) references student,
foreign key (course_id, sec_id, semester, year) references section
);
说明:
- 主键:在r中属性值唯一标识元组,不允许为空值,用来唯一确定一个entity。
- 外键:在r中属性值引用另一个关系s中的主键,用来建立关系之间的联系。
2. Drop and Alter Table Constructs
在 SQL 中,DROP TABLE 和 ALTER TABLE 是两种用于管理数据库表的命令。它们分别用于删除表和修改表的结构。以下是它们的详细介绍:
1. DROP TABLE
功能 DROP TABLE 命令用于从数据库中永久删除一个表以及表中存储的所有数据。 delete from table 用于删除表中的所有数据,但保留表结构。
1
2
3
#### **语法**
```sql
DROP TABLE table_name;
特性
- 不可恢复性:删除表后,表结构和数据都会被永久删除,无法通过普通 SQL 恢复。
- 依赖关系:如果其他表有外键依赖于被删除的表,
DROP TABLE通常会失败,除非显式移除依赖关系。 - 选项:
IF EXISTS:防止删除一个不存在的表时抛出错误。
示例
1
2
3
4
5
-- 删除名为 Students 的表
DROP TABLE Students;
-- 删除表时先检查是否存在
DROP TABLE IF EXISTS Students;
2. ALTER TABLE
功能 ALTER TABLE 命令用于修改现有表的结构,例如添加列、删除列、更改列类型或名称,以及设置约束。
语法
1
ALTER TABLE table_name action;
其中,action 是具体的修改操作。常见的action包括:
- add A B: A 是属性名,B是属性的domain,用于添加新列;
- drop A: A 是属性名,用于删除列;
常用操作
- 添加列
1
ALTER TABLE table_name ADD column_name data_type [constraint];
示例:
1
ALTER TABLE Students ADD Age INT;
- 删除列
1
ALTER TABLE table_name DROP COLUMN column_name;
示例:
1
ALTER TABLE Students DROP COLUMN Age;
- 修改列
- 修改列的数据类型:
1
ALTER TABLE table_name MODIFY column_name new_data_type;
- 重命名列(部分数据库使用不同语法):
1
ALTER TABLE table_name RENAME COLUMN old_name TO new_name;
- 修改列的数据类型:
- 添加或删除约束
- 添加约束:
1
ALTER TABLE table_name ADD CONSTRAINT constraint_name constraint_definition;
- 删除约束:
1
ALTER TABLE table_name DROP CONSTRAINT constraint_name;
- 添加约束:
- 重命名表
1
ALTER TABLE old_table_name RENAME TO new_table_name;
通过这些命令,数据库管理员可以灵活管理数据库表的生命周期和结构。
3. select clause
查询语句
1
select A1, A2, ... from r where P;
A1,A2是查询到表属性,r是查询的表,P是筛选条件。
SQL允许表和select返回的结果中出现冗余数据,可以使用distinct关键字去除重复数据。
1
select distinct dept_name from instructor;
- select中的*表示所有属性
- select中允许出现算术表达式:
1
select ID, name, salary * 1.1 from instructor;
select查询中的基本概念
- 关系模型:select返回的结果实际上是一个relation schema r
- 元组操作:r中的entity是tuple
- 属性操作:r的列称为属性
- 投影 Projection:select返回的结果是r的一个子集,称为投影
4. where clause
用于指定查询结果必须满足的条件,类似于关系代数中的选择谓词。在执行where中的条件后,r中的元组会被过滤,最后返回select的属性的列集合。
where子句的逻辑操作
- and
- or
- not
5. from clause
指定查询中设计的表或者视图,当from中有多个表时,会对这些表做笛卡尔积操作进行组合。要了解笛卡尔积如何实际操作。
在sql中,笛卡尔积被显式声明为inner join。
6. joins
natural join
NATURAL JOIN 会自动识别两个表中名称相同的列,然后基于这些列进行值的匹配,仅保留一份公共列。
操作过程:
- 找到共同属性名
- 进行匹配
问题:不同表中同名列可能引发错误 如果表中存在同名但无关的列,NATURAL JOIN 会将这些列错误地当作连接条件,导致不正确的结果。就是两张表中虽然有同名属性,当这两个属性在现实中的意义不同,则不能使用NATURAL JOIN。
7. rename
rename操作用于重命名表中的属性,可以使用as关键字来重命名属性。
1
select ID as identification, name as instructor_name from instructor;
可以将带有逻辑运算的属性进行重命名
8. string operations
- like:常用于where进行模糊查询,查询模式中可以使用%和_通配符
- %:匹配任意字符(包括0个字符)
- _:匹配一个字符
1
select * from instructor where name like '%dar%';
常见用法:
- 匹配以 “a” 开头的所有名字:
name like 'a%' - 匹配以 “abc” 结尾的所有名字:
name like '%abc' - 匹配第五个字符是 “x” 的名字:
name like '____x%'
9. ordering the output
order by 子句用于对查询结果进行排序,可以按照一个或多个属性进行排序,可以指定升序或降序。(默认为升序)
1
select * from instructor order by name;
10. between
between操作符用于在指定的范围内查找值,可以用于数值、文本和日期数据类型。
1
select * from instructor where salary between 50000 and 60000;
11. set operations
集合操作
- union: 合并两个结果集,去除重复项
- intersect:返回两个结果集的交集,即仅包含同时出现在两个结果集中的元素,且会去除重复项。
- except:返回第一个结果集中存在,但第二个结果集中不存在的元素,且会去除重复项。
如果想要保留重复项:加个all
12. null values
null值是数据库中的一个特殊值,表示未知或不适用的值。null值不等于任何值,包括null值本身。
包含null的逻辑运算:
- 任何的关系运行包含null均返回null
- 三元逻辑运算中包含null:
- and:如果有true返回null,有false返回false,全为null返回null
- or:如果有true返回true,有false返回null,全为null返回null
- not:返回null
13. aggregate functions
聚合函数是用于对一组值进行计算并返回单个值的函数。常见的聚合函数有:
- avg: 返回一组值的平均值
- min: 返回一组值的最小值
- max:返回一组值的最大值
- sum:返回一组值的总和
- count:返回一组值的数量
伴随聚合函数出现的group by子句,用于按某些列对结果进行分组,并对每个组应用聚合函数。
使用groupby和aggregate函数的规则
- 在 SELECT 子句中,如果使用了聚合函数外的列,这些列必须出现在 GROUP BY 子句中。
- 非聚合列:如果你在 SELECT 子句中选择了一个列,并且该列没有被聚合函数包裹,那么它必须出现在 GROUP BY 子句中。
如果aggregate函数中的列的domain存在null值呢?
- sum(*):它会 忽略 NULL 值,仅计算非 NULL 的值。如果该列没有任何非 NULL 值(即所有值都是 NULL),则 SUM() 会返回 NULL。
- COUNT(*) 会 计算所有的行,包括那些包含 NULL 的行。它不会忽略 NULL 值,而是统计行的数量, 哪怕全是null
- 其他聚合函数 (AVG(), MIN(), MAX()):这些函数都会 忽略 NULL 值,只计算非 NULL 的数据。
sql关键字执行顺序
14. with cluase
允许你定义临时的视图view或查询结果集(称为公用表表达式CTE),这在同一上下文中反复使用同一个查询时将非常有用。
语法:
1
2
3
4
5
WITH cte_name(cte_attr1, cte_attr2, ...) AS (
SELECT column1, column2, ...
FROM table_name
WHERE condition
)
复杂用法:可以将查询拆分成多个子查询,并将每次子查询的结果储存在一个with的视图中供下次子查询使用。
15. scalar subqueries 标量子查询
标量子查询是一种返回单个值的子查询,用于期望返回但一直的上下文中。可以作为某些列的计算结果,或者某个条件的比较值
1
2
3
select ID, name,
(select max(salary) from instructor) as max_salary
from instructor;
注意事项:子查询返回多于一个结果时的错误
16. nested subqueries 嵌套子查询
在子查询中嵌套子查询,可以实现更复杂的查询操作。
例子:查找所有薪资高于某些部门平均薪资的讲师,并且该部门的预算高于 100,000:
1
2
3
4
5
6
7
8
9
10
11
SELECT name
FROM instructor
WHERE dept_name IN (
SELECT dept_name
FROM department
WHERE budget > 100000
) AND salary > (
SELECT AVG(salary)
FROM instructor
WHERE dept_name = instructor.dept_name
);
17. subqueries in the from clause
在 SQL 中,可以在 FROM 子句中使用子查询,这样的子查询被称为派生表(或内联视图)。这种方法在你需要先进行计算或聚合操作,然后基于结果进行筛选时非常有用。当子查询出现在 FROM 子句时,它就像一个临时表一样可以被外部查询引用。
例子:查找那些平均工资超过 42,000 的部门的讲师的平均工资。
1
2
3
4
5
6
7
8
SELECT dept_name, avg_salary
FROM (
SELECT dept_name, AVG(salary) AS avg_salary
FROM instructor
GROUP BY dept_name
)
WHERE avg_salary > 42000;
18. 对数据库的修改:delete and insert
- delete: 用于删除表中的行,可以使用where子句指定删除的条件。
1
delete from instructor where dept_name = 'Biology';
- insert: 用于向表中插入新行,可以指定插入的列和值。
1
insert into instructor values ('231323', 'Green', 'Music', 10000);
Intermediate SQL 中级SQL
Joined Relations
在SQL中,”Joined Relations”(连接关系)是指通过某种条件将两个或多个表的数据结合起来,以便查询出所需的信息。连接操作是SQL查询中非常重要的一部分,尤其在处理复杂查询时更为常见。以下是几种常见的连接类型:
内连接(INNER JOIN): 内连接是最常用的连接类型。它返回两个表中满足连接条件的记录。只有在两个表中都有匹配的记录时,结果集才会包含这些记录。
左连接(LEFT JOIN): 左连接返回左表中的所有记录,以及右表中满足连接条件的记录。如果右表中没有匹配的记录,则结果集中包含左表中的记录,并且右表的字段为NULL。
右连接(RIGHT JOIN): 右连接与左连接类似,但返回右表中的所有记录,以及左表中满足连接条件的记录。如果左表中没有匹配的记录,则结果集中包含右表中的记录,并且左表的字段为NULL。
全连接(FULL JOIN): 全连接返回两个表中的所有记录,当其中一个表中没有匹配的记录时,结果集中包含NULL值。
交叉连接(CROSS JOIN): 交叉连接返回两个表的笛卡尔积,即每个表中的每一行都与另一个表中的每一行进行组合。
自然连接(NATURAL JOIN): 自然连接是一种特殊的内连接,它自动基于两个表中同名且同类型的列进行连接。
外连接 outer Join
当其中一个表中没有匹配的记录时,如果希望连接另一个表中的所有成员,但由于某成员在另一个表中没有记录,导致无法匹配,无法出现在新创建的表中。
outer join:在通过在结果中创建包含空值元组的方式,保留那些丢失的元组。
- left outer join: 只保留outer join 左边的关系中的元组
1 2
select * form table1 left outer join table2 on table1.column_name = table2.column_name;
- right outer join: 只保留outer join 右边的关系中的元组
- full outer join: 保留outer join 两边的关系中的元组
内连接 inner join
不保留那些没有匹配的元组,只保留那些匹配的元组。也就是普通连接,可用join替代inner join
1
2
SELECT column_name(s)
FROM table1 join table2 on table1.column_name = table2.column_name;
视图 view
不实际存在的虚拟的关系。存在理由:让用户看到所有的实际存在的逻辑关系可能是不安全的,需要虚拟的关系来隐藏某些隐私的关系和数据。
视图:任何不是逻辑模型的一部分,作为虚关系对用户可见的关系称为试图。
1
2
create view v as
<query expression>: //查询语句
view不进行预计算和储存,当数据库存储与view相关的查询表达式,view被访问时,才会执行查询语句,因此view是在需要的时候被创建的。
使用view
数据库不提前存储view的数据,只有在访问到view时,实时地访问view内的查询语句,以防止view数据落后。
物化视图
materialized view:物化视图保证定义物化视图的关系被修改时,定义视图的查询结果也会相应地改变。
materialized view maintenance:维护物化视图更新的过程
视图更新
使用视图的困难在于:如果只是用view进行查询操作,没有问题;如果用view来进行增删改操作,困难就出现了,我们该如何将view的修改映射为实体关系的修改。
为方便理解,下面将举实际例子:
1
2
3
create view facully as
select ID, name, dept_name
from instructor;
向view中插入新的数据:
1
2
insert into facully
values ('231323', 'Green', 'Music');
数据库会实际想instructor插入
1
2
insert into instructor
values ('231323', 'Green', 'Music', null)
但是如果view有多个关系得来时,上述方法将不可能实现。
transaction 事务
查询和更新语句的序列组成。
- commit work:提交操作的结果
- rollback work:回滚未提交的操作的结果
通过这样实现原子操作:atomic op
完整性约束
参照完整性:表示的是两个关系之间的联系、是表与表之间的引用。对应的就是外键。 实体完整性:用来唯一表示实体的要求。不能为空,需要唯一确认,表示的是这一条记录的实体的完整唯一,通常用主键表示,不为空且不重复
某个表使用另一张表的主键作为属性,成为外键,表示两张表之间存在引用的关系,引用方依赖于被引用方。
保证数据一致性
- not null 约束
1
name varchar(20) not null
- unique 约束: 不允许上述属性出现两个元组zhixi
unique(Aj1, Aj2, ... , Ajm) - check
模块四:数据库设计
Entity-Relationship Model / ER模型
modeling
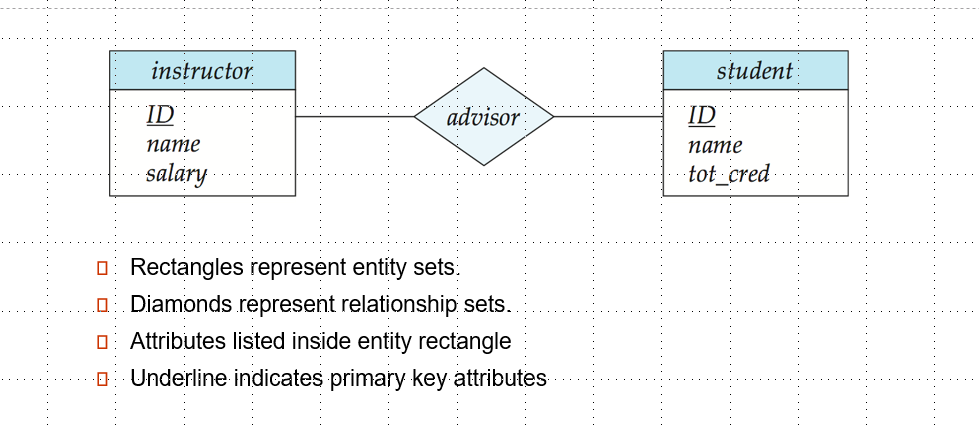
数据库可以被建模为一个个彼此之间有联系的实体,实体在数据库中表现为对象,实体集表现为表。实体具有属性,实体集是指具有相同属性的实体的集合。
relationship sets relationship :实体之间的联系。

relationship set:在大于两个的来自不同实体集的实体之间的数学关系。
binary relationship:两个实体集之间的关系。
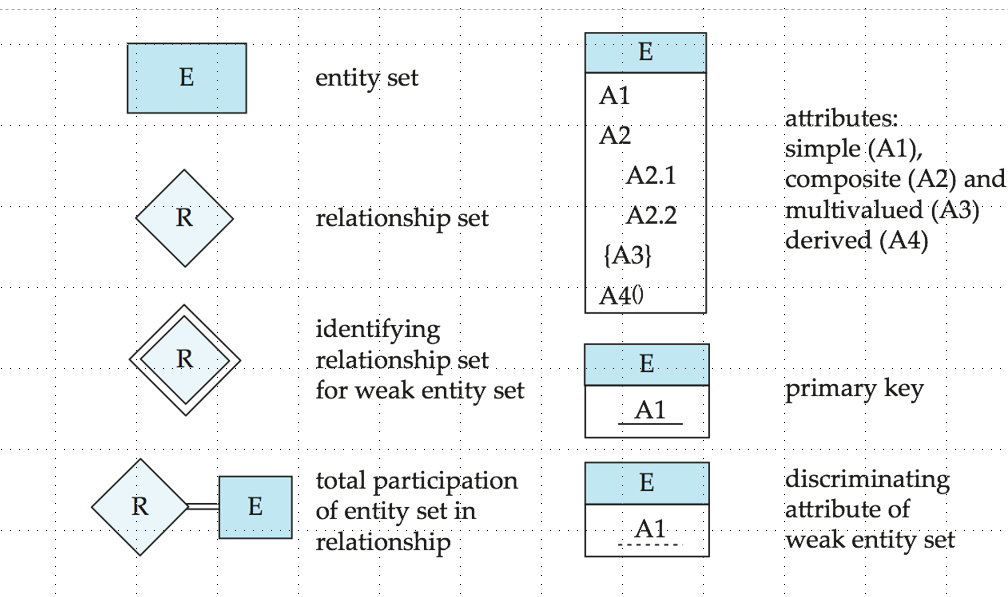
Attributes 实体可由多个attributes表示
- simple / 单属性
- composite / 复合属性
- Single-valued and multivalued attributes / 单值和多值属性
- derived / 派生属性 可以由其他属性计算得到
Roles / 角色
constraints / 约束
约束是对数据库中数据的限制条件,用于保证数据的完整性和一致性。
- mapping cardinality constraints / 映射基数约束

- keys for relationship sets / 键

ER Diagram
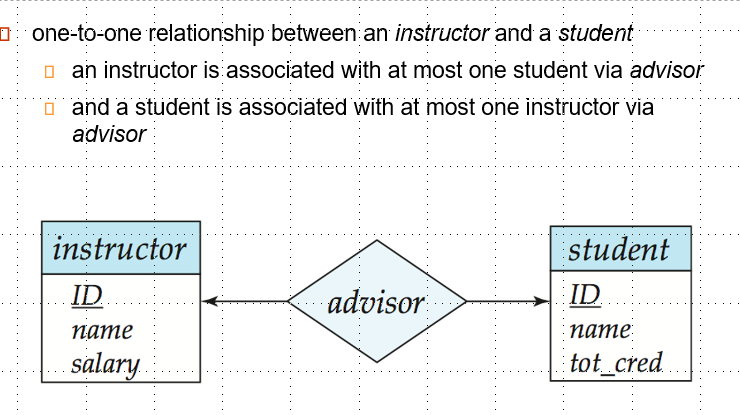
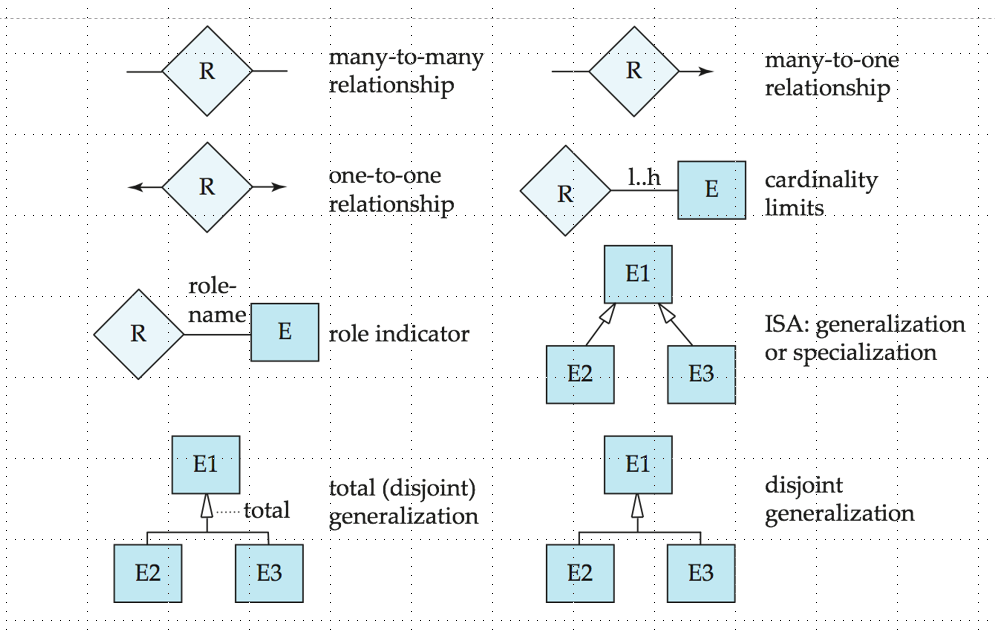
用单箭头表示One关系,用直线表示Many关系
- One-to-One
- One-to-Many
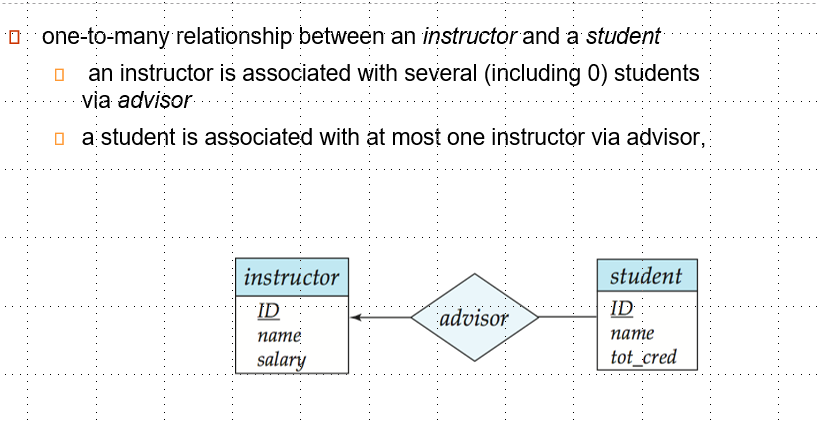
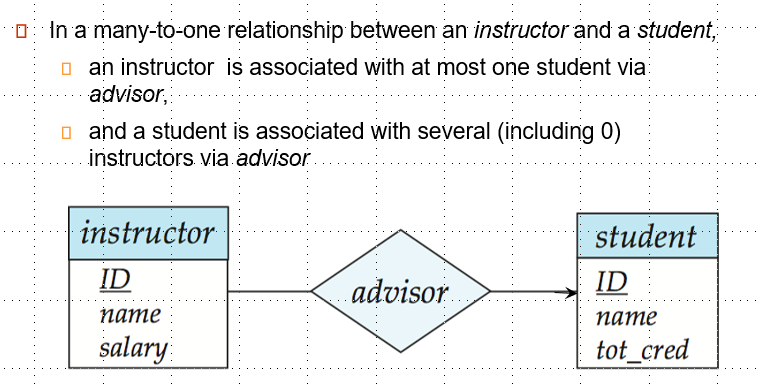
- Many-to-One
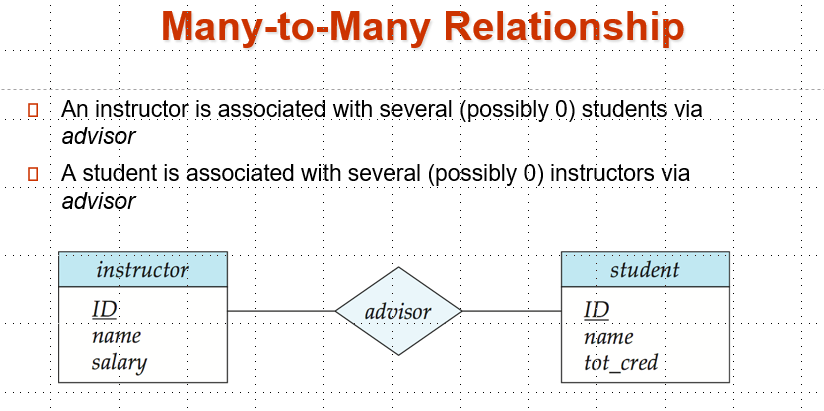
- Many-to-Many
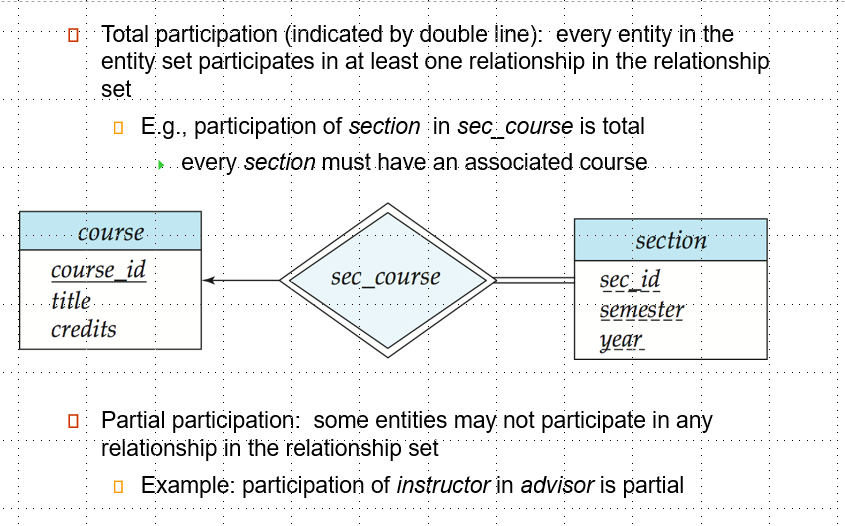
Participation of an Entity Set in a Relationship Set / 实体集在关系集中的参与度
- total participation / 完全参与:使用双线表示或者0..*
- partial participation / 部分参与:使用单线表示或者1..1
Weak Entity Sets / 弱实体集
定义:
- 不能独立存在,依赖于其他实体集存在的实体集
- 没有自己的主键属性
- 需要依赖强实体集的主键来唯一标识
Identifying Relationship / 标识联系
- 用于将弱实体集与其依赖的强实体集联系起来
- 这种关系是多对一的
- 弱实体基是完全参与的
- 标识联系在 ER 图中用双菱形表示。
Discriminator / Partial Key / 判别属性
弱实体集的判别属性是一组属性,用于区分弱实体集中所有实体实例。使用下划虚线表示。
弱实体集的主键:弱实体集的主键由标识实体集的主键和弱实体集的判别属性共同组成。
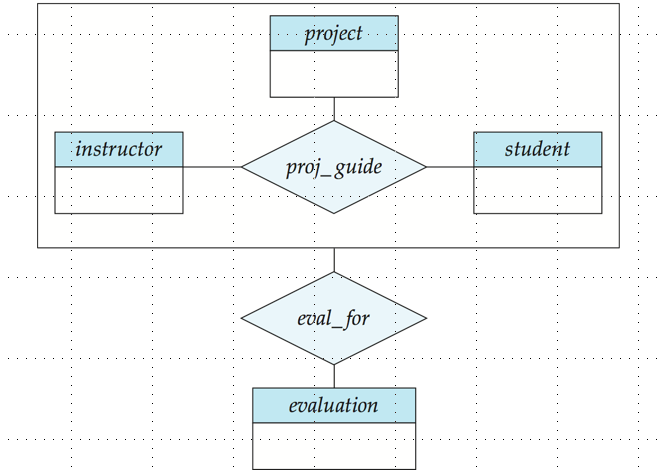
Example:E-R Diagram for a University Enterprise**
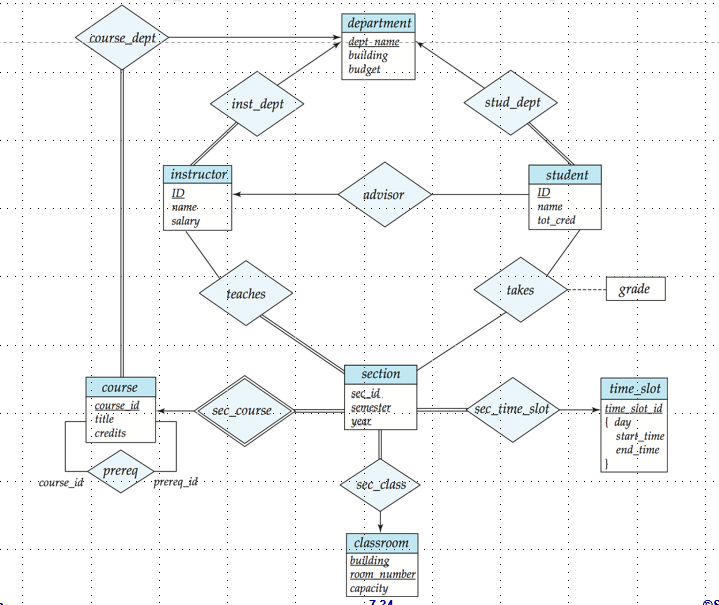
Reduction to Relation Schemas / 关系模式的转换
去掉冗余的1-1, 1-m联系
ER Diagram -> shcemas
step:
- entities -> schemas
- relationships -> schemas
- Optimization,Remove redundant schemas
设计relationship的技巧是把relationship视为两个实体集之间的发生的动作
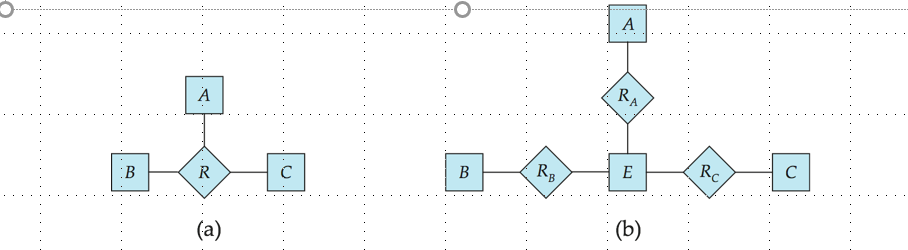
二元关系集与n元关系集
尽管可以用多个不同的二元关系集来替换任何非二元(n元,n > 2)关系集,但n元关系集更清楚地表明多个实体参与了一个单一的关系。
有些关系用非二元关系来表示优于用二元关系来表示,因为这样可以更清楚地表达实体之间的关系。
将非二元关系转化为二元关系
假设有如下二元关系:
- RA, relating E and A
- RB, relating E and B
- RC, relating E and C
step1:拆功能键一个特殊的实体集E
step2:将所有关系中的属性加入到E中
step3,对于R中的每个关系,创建:
- a new entity e_i in the E
- add (e_i, a) to RA
- add (e_i, b) to RB
- add (e_i, c) to RC
Extend ER Features
Specialization / 特化
专门化:将一个实体集分解为多个实体集,每个实体集包含实体集的子集,每个子集有自己的属性。是一个自上而下的过程。
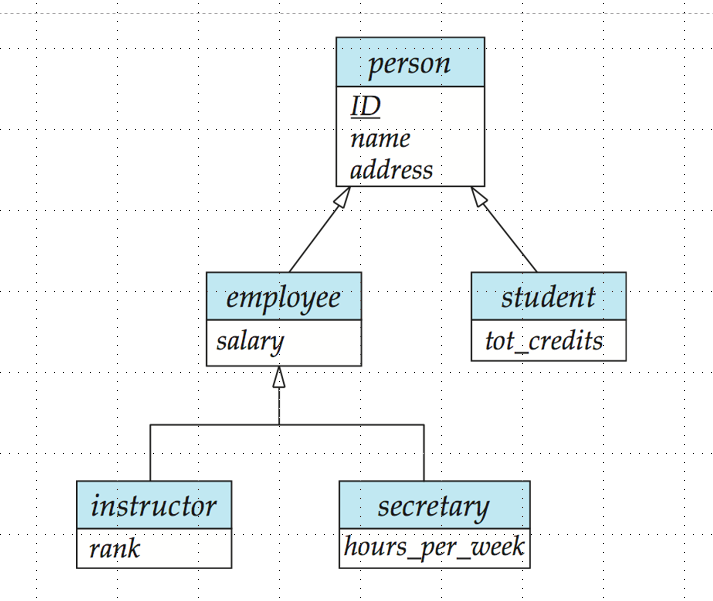
空心箭头表示继承关系。
Generalization / 泛化
泛化:将多个实体集合并为一个实体集,每个实体集包含实体集的父集,每个父集有自己的属性。是一个自下而上的过程。
Aggregation / 聚合
聚合(Aggregation)是一种将多个实体和关系集组合成一个更高层次的抽象的技术。它用于表示一个关系集本身可以作为另一个关系集的实体参与者。
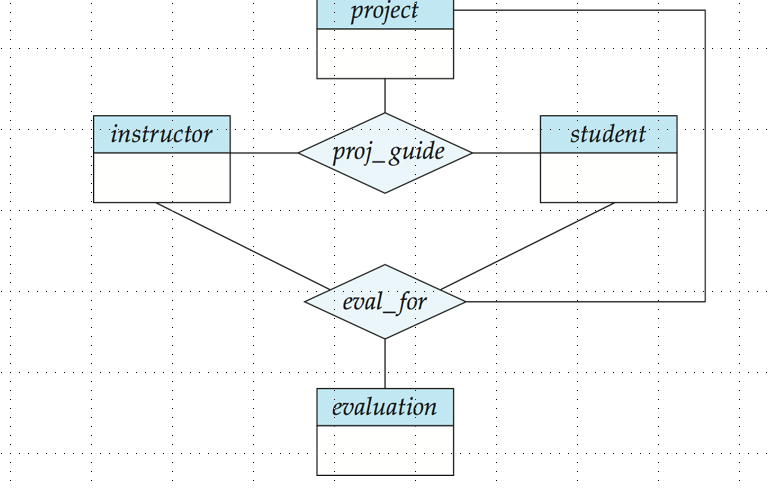
总结:ER图中的标志 规范画图
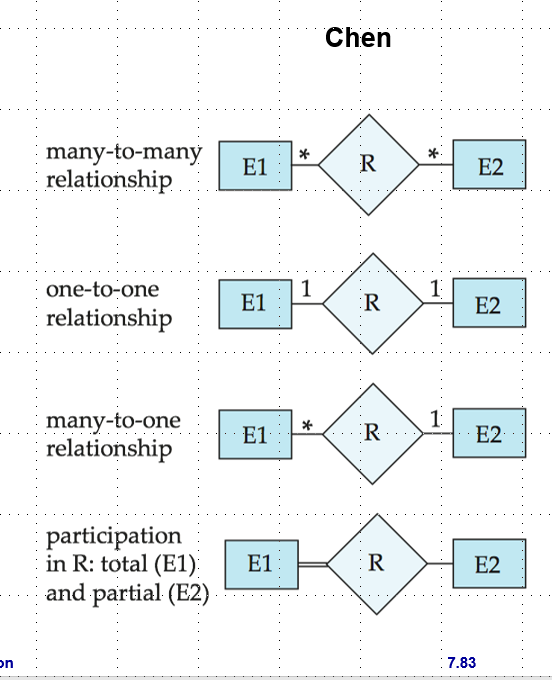
Relational Database Design
Combine Schemas And Smaller Schemas (decompose Schemas)
Combine Schemas 将多个关系合并为一个关系,也可以说是将多个数据库模式合并为一个数据库模式这样做的好处是可以减少关系之间的连接操作,提高查询效率。
Decombine Schemas 最小化模式的数量,是Combine Schemas的反操作,将一个关系分解为多个关系,减少数据冗余,提高查找效率。
functional dependency: 函数依赖,是指一个属性的值依赖于另一个属性的值,这种依赖关系是一种约束,是一种完整性约束。及一对一的关系。 dept_name -> building dept_name -> budget
lossy decomposition:在分解关系时,如果分解后的关系不能恢复原来的关系,那么这种分解就是lossy decomposition。
lossless join decomposition:在分解关系时,如果分解后的关系能够通过连接操作恢复原来的关系,那么这种分解就是lossless join decomposition。
good: 一个关系模式R的分解D是good的,如果对于R的每一个实例r,通过D的连接操作能够恢复r。不存在冗余的情况。如何实现good的分解呢?可以使用BCNF分解。good的分解定义是无损分解(使用BCNF)和依赖保存(使用3NF)。需要进行权衡。
First Normal Form
域的原子性(Domain is atomic):关系模式的每一个属性都是不可再分的原子值。如果所有的域的所有属性都是原子的,那么关系模式就是第一范式(First Normal Form)的。
Non-atomic values complicate storage and encourage redundant (repeated) storage of data.非原子值使存储复杂化,并鼓励数据的冗余(重复)存储。
Atomicity 是域如何定义其组成的元素的,比如一个域是String,那么这个String是不可再分的,是原子的。
- Functional Dependengy 函数依赖 用于描述关系模式中属性之间的依赖关系。具体来说,函数依赖是指在一个关系模式中,如果属性集X的值唯一地决定了属性集Y的值,那么称Y函数依赖于X,记作X -> Y。函数依赖是键的概念(notion)的推广(generalization)。通俗点说,就是一个X的值不能决定多个Y的值,但一个Y的值可以由多个X的值决定。
例子 假设有一个关系模式R,包含属性A, B, C。如果对于R的每一个实例r中的任意两个元组t1和t2,只要t1[A] = t2[A],就有t1[B] = t2[B],那么我们说B函数依赖于A,记作A -> B。
形式定义 给定一个关系模式R和它的一个实例r,属性集X和Y是R的子集。如果对于r中的任意两个元组t1和t2,只要t1[X] = t2[X],就有t1[Y] = t2[Y],那么称Y函数依赖于X,记作X -> Y。
完全函数依赖和部分函数依赖 完全函数依赖:如果Y函数依赖于X,并且X的任何真子集都不能决定Y,那么称Y完全函数依赖于X。 部分函数依赖:如果Y函数依赖于X,但X的某个真子集也能决定Y,那么称Y部分函数依赖于X。 传递函数依赖 如果X -> Y,且Y -> Z,那么根据传递性,可以得到X -> Z。这种依赖关系称为传递函数依赖。
作用 函数依赖在数据库规范化过程中起着关键作用,通过分析和消除不必要的函数依赖,可以减少数据冗余,提高数据一致性。
示例 假设有一个学生关系模式Student(StudentID, Name, Major, Advisor),其中:
StudentID -> Name, Major, Advisor Name -> Major 在这个例子中,StudentID唯一确定了学生的Name、Major和Advisor,而Name唯一确定了Major。
Third Normal Form
Boyce-Codd Normal Form (BCNF) Boyce-Codd Normal Form(BCNF)是数据库规范化的一种形式,它是第三范式(3NF)的一个特例。BCNF是指一个关系模式R,对于R的每一个非平凡函数依赖X -> Y,X都是R的候选键。换句话说,如果一个关系模式R的每一个非平凡函数依赖都是由R的候选键决定的,那么R就是BCNF的。
3NF 一个关系模式R是3NF的,如果R中存在的每一个函数依赖a -> b, 至少包含以下三种情况:
- b 属于 a
- a 是R的superkey
- 对于b-a的每一个属性A是R的candidate key
如果一个关系模式R是BCNF,那么R一定是3NF的。但是反过来不一定成立,即3NF不一定是BCNF。
- superkey and candidate key
解释如下:
- K 是关系模式 R 的超键(superkey)当且仅当 K -> R:
- 这意味着 K 中的属性集合可以唯一地标识关系模式 R 中的每一个元组。换句话说,K 的值可以唯一确定 R 中的每一个记录。
- K 是关系模式 R 的候选键(candidate key)当且仅当:
- K -> R,并且
- 对于 K 的任何真子集 α,都不存在 α -> R:
- 这意味着 K 不仅是一个超键,而且是最小的超键。即,K 中的任何一个属性都不能被去掉,否则它将不再是一个超键。
总结:
- 超键是能够唯一标识关系模式中每一个元组的属性集合。
- 候选键是最小的超键,即不能再去掉任何属性的超键。
函数依赖是平凡的(trivial),如果被关系的所有实例所满足。换句话说,右边的属性是左边属性的子集时,函数依赖是平凡的。
- 函数依赖的应用
- 检查关系模式是否符合提供的一组函数依赖。如果关系模式r满足函数依赖集合F,那么r satisfist F。
- F holds on r: 如果关系模式r满足函数依赖集合F,那么F holds on r。
Lossless-join Decomposition
如何定义一个关系模式的分解是lossless-join的呢?
一个关系模式R的分解D是lossless-join的,如果对于R的每一个实例r,通过D的连接操作能够恢复r。换句话说,如果R通过D的连接操作能够恢复,那么R的分解D是lossless-join的。
需要满足下面的函数依赖: * R1 ∩ R2 -> R1 * R1 ∩ R2 -> R2
注意:这些条件是必要条件,但不是充分条件。也就是说,如果一个分解满足这些条件,那么它是lossless-join的,但反过来不一定成立。
Closure of a set of functional dependencies 依赖闭包
F+用来表示F的闭包,即F的所有推导出来的函数依赖集合。F+是F的最小超集,满足以下条件: * F+ 包含F中的所有函数依赖 * F+ 包含F中的所有推导出来的函数依赖
如何找到F的闭宝呢?可以通过重复的使用Armstrong’s Axioms,知道不能再推导出新的函数依赖为止。 Armstrong’s Axioms:
- Reflexivity: 如果X 是属性集合A的子集,那么A -> X
- Augmentation:若α→β成立且γ为一属性集,则γα→γβ
Transitivity: 如果A -> B,B -> C,那么 A -> C
- Procedure for Computing F+ 计算闭包范式
1 2 3 4 5 6 7 8
repeat for each functional dependency f in F+ apply reflexivity and augmentation rules on f add the resulting functional dependencies to F + for each pair of functional dependencies f1and f2 in F + if f1 and f2 can be combined using transitivity then add the resulting functional dependency to F + until F + does not change any further
Addtional rules:
- Union: 如果A -> B 和 A -> C,那么 A -> BC
- Decomposition: 如果A -> BC,那么 A -> B 和 A -> C
- Pseudotransitivity: 如果A -> B 和 BC -> D,那么 AC -> D 均可以使用Armstrong’s Axioms来推导。
Closure of Attribute Sets
定义: a+ = {A: a -> A holds under functional dependencies F}
- 计算a+算法
1 2 3 4 5 6
result := a; while (changes to result) do for each b -> y in F do begin if b 为 result的子集 then result := result U y endfunctional dependency and attribute closure: Let R be a relation schema with a functional dependency F, and let A be a set of attributes of R. The closure of A under F, denoted A+, is the set of attributes B such that A -> B holds under F.
应用:判断一个属性集合是否是一个超键,可以计算它的闭包,如果闭包包含了所有的属性,那么这个属性集合就是一个超键。
Attribute Closure and superkey 应用上面介绍的理论就可以判断a是否为R的一个超键,只需要计算a的闭包,如果闭包包含了R的所有属性,那么a就是R的一个超键。
Attribute Closure and functional dependency Closure 计算函数依赖集合F的闭包
- F -> F+
- 对于R中的每个属性y,计算y闭包y+
- 对于y+中的每个属性s,计算F+ <- F+ U {y -> s}
Boyce-Codd Normal Form (BCNF)
上面已经初步介绍BCNF,接下来在具备函数依赖闭包和属性闭包的基础上,进一步深入讨论BCNF。
- 如何检查是否存在非平凡函数依赖a->b,导致关系模式不符合BCNF?
1 2
compute a+ verify if a+ contains all attributes of R
- 如何检查一个关系模式是否符合BCNF?
1 2
for each functional a -> b check if it violates BCNF
- decomposing a schema into BCNF 思想:将一个关系模式分解为多个关系模式,使得每个关系模式都符合BCNF。
存在非平凡函数依赖a->b
将R分解为R1(a, b)和R2(a, R - b)
- BNCF Decomposition Algorithm 已知schema R 和 函数依赖F。如果R不是BCNF,说明存在坏函数依赖a->b导致,并且a不是超码和b的超集对于这样的坏函数依赖存在一下两种可能情况
- a 并 b = 空集
- a 并 b != 空集
算法:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
result := {R};
Ri := {R}; // added for better understanding
done := false;
compute F+;
while (not done) do
if (there is a schema Ri in result that is not in BCNF) then
begin
let a -> b be a nontrivial functional dependency that
holds on Ri such that a -> Ri is not in F+,
and a -> b ≠ ∅;
result := (result – Ri) ∪ (Ri – b) ∪ (a, b);
end
else
done := true;
Third Normal Form:Motivation
定义weaker normal form called 3NF
- 允许redundancy
- functional dependencies can be checked on individual relations without computing a join
- 存在lossless-join depency-preserving
判断: A relation schema R 是 3NF 的,如果对于R的每一个非平凡函数依赖a -> b,要么
- a 是R的超码
- b 是a的子集
- 对于每个属性A in b-a 是R的候选码
如果R是BCNF,那么R一定是3NF的。但是反过来不一定成立,即3NF不一定是BCNF。
第三个条件是BCNF的minimal relaxation,可以保证依赖保持(dependency preservation)
Canonical Cover 规范覆盖
函数依赖集中存在不必要的函数依赖,可以通过规范覆盖来消除这些不必要的函数依赖。函数依赖的最小集被成为F的规范覆盖。
如果计算一个函数依赖集合的规范覆盖:
- Extraneous Attributes 函数依赖集合F中存在冗余的属性,可以通过规范覆盖来消除这些冗余的属性。冗余属性是指在函数依赖集合F中,存在一个函数依赖a -> b,其中b中包含了a的真子集。
如何测试一个Attribute是否是冗余的呢?
- 计算a+
- 如果a+ 包含了b,那么b是冗余的
关系型数据库设计相关笔记:

模块五:检索 / 索引
基本概念
索引: 对存储在自盘目录进行分类整理。目的:更快的查询速度。
- 顺序索引 / Oedered Indices:按某个属性值进行排序。
- 散列索引 / Hash Indices:类似哈希表。
索引评价:
- 访问类型 / Access Types
- 访问时间 / Access Time
- 插入时间 / Insertion Time
- 删除时间 / Deletion Time
- 空间开销 / Space Overhead
顺序索引
- 搜索码在文件内是否有序
- Primary Index / 主
- Secondary index / 辅
- 按索引项是否完备
- Dense Index / 稠密
- Sparse Index / 稀疏
- Multilevel Index / 多级
顺序文件
Ordered File:ordered by search-key
主索引 = 聚簇索引:建立在有序文件中的有序字段上
某个字段是有序的,那么这个字段就是聚簇索引。
稠密索引 / Dense Index
每个搜索码值都有一个索引项,索引项按搜索码排序。换句话说,稠密索引为表中的每一行数据都创建了一个索引项,并且这些索引项按照搜索码值的顺序排列。
稀疏索引 / Sparse Index 稀疏索引(Sparse Index)是一种索引结构,其中并不是每个搜索码值都有一个对应的索引项。相反,稀疏索引只为部分搜索码值创建索引项,这些索引项通常指向数据块的起始位置。稀疏索引的优点是占用的存储空间较小,但查询时可能需要扫描更多的数据块。·
多级索引 / Multi-Level Index
B+树索引文件
B+树的内部节点存储索引值和指向子节点的指针,而叶子节点存储实际的数据或指向数据记录的指针。
- 所有根节点到叶子节点的长度相同
- 非叶子/根的节点的孩子数为[
⌈m/2⌉, m] (m为B+树的阶) / B+树的阶表示每个节点最多可以有的子节点的个数。 - 叶子节点的个数为[
⌈m - 1/2⌉, n-1] - B+树的高度height:
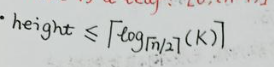 (K是叶子节点个数,也就是search-key value的个数)
(K是叶子节点个数,也就是search-key value的个数)
B+树的增删查改
静态散列 / static hashing
bucket: 持有一个或多个数据项的存储单元,通常是一个磁盘块。使用哈希函数将search-key映射到bucket。
hash function
在哈希文件组织中,我们使用哈希函数直接从记录的搜索键值获取其桶(bucket)。哈希函数将搜索键值映射到一个桶号,从而可以快速定位记录所在的桶。
- 最差的哈希函数会将所有搜索键值映射到同一个桶中,这使得访问时间与文件中搜索键值的数量成正比。
- 理想的哈希函数是均匀的,即每个桶被分配相同数量的搜索键值。
- 理想的哈希函数是随机的,因此每个桶将分配相同数量的记录,而不管文件中搜索键值的实际分布。
- 典型的哈希函数对搜索键的内部二进制表示进行计算。例如,对于字符串搜索键,可以计算字符串中所有字符的二进制表示的总和,然后将总和对桶的数量取模得到哈希值。
handling of bucket overflows
桶溢出可能发生的原因有:
- 桶数量不足
- 记录分布的偏斜(Skew),这可能由于以下两个原因:
- 非随机:多个记录具有相同的搜索键值
- 非均匀:选择的哈希函数产生了非均匀的键值分布
虽然可以减少桶溢出的概率,但无法完全消除;通常通过使用溢出桶来处理。
解决:
Overflow chaining – the overflow buckets of a given bucket are chained together in a linked list.
Hash Indices
哈希不仅可以用于文件组织,还可以用于创建索引结构。 哈希索引将搜索键及其关联的记录指针组织成哈希文件结构。 严格来说,哈希索引总是次级索引。 如果文件本身是使用哈希组织的,那么使用相同搜索键的单独主哈希索引是没有必要的。 然而,我们使用“哈希索引”一词来指代次级索引结构和哈希组织的文件。
查询
step:
- 解析和翻译:将查询转换为其内部形式。然后将其转换为关系代数
- 优化:解析器检查语法,验证关系
- 评价:查询执行引擎采用查询评估计划,执行该计划,并返回查询的答案。
事务调度
事务调度的准则
- 一组事务的调度必须保证:包含了所有事务的操作指令;一个事务内部的指令顺序必须保持不变
- 并行事务调度必须保证:可视性化,将所有可能的串行调度结果推演一遍,对于某个具体的并行调度再执行一遍,看是否能与某个串行调度的结果相同
- 判断可串性化的充分条件:冲突可串行化(冲突可串行化一定是可串行化调度,但可串行化调度不一定是冲突可串行化)
冲突操作:不同事物对同一数据进行读和写;不同事物对同一数据分别进行写和写
冲突可串行化调度即不交换不同事物的冲突操作次序,也不交换同一事物的两个操作的次序。但可以交换不同事务对不同数据各种操作次序,也可以交换不同事物对同一数据的读取操作次序。
封锁
- X锁:写锁,某事务对数据对象上锁后,可读取和修改该数据对象,其他事务不可再对该数据对象添加锁
- S锁:读锁,某事物对数据上锁后,可读取但是不可修改该数据对象,其他事务可以对该数据对象添加读锁但不可以添加x锁
- 封锁协议:
- 一级封锁协议:写前加写锁,事务结束释放写锁;可防止丢失修改
- 二级封锁协议:写前加写锁,读前加读锁,读完释放读锁,事务结束释放写锁;可防止修改丢失和读脏数据;
- 三级封锁协议(支持一致性维护):写前加写锁,读前加读锁,事务结束释放各锁;可防止丢失修改,读脏数据和不可重复读
- 两段锁协议(2PL):事务在对任何数据进行读写前,需要获得对该数据的封锁;而当事务在释放任何一个封锁后,不可再获得任何的其他封锁。
Database Modiification 数据库修改
immediate-modification scheme:允许一个未提交的事务对缓存或者磁盘本身进行修改,但是这种修改是立即生效的,即使事务未提交。
deferred-modification scheme:允许一个未提交的事务对缓存或者磁盘本身进行修改,但是这种修改是延迟生效的,即使事务未提交。在事务提交后生效。